令牌化¶
本模块提供题目的令牌化解析,将带公式、图片的句子切分为若干标记的过程。每个标记为一个“令牌”(token),方便后续向量化表征试题。
此模块实际上是将 成分分解 得到的不同成分(文本、公式、图片等)的 语法解析 结果做进一步处理,得到最终的多模态的令牌序列。
Note
在自然语言处理中,令牌化通常指分词,即将一个句子转化为词序列。针对多模态的教育资源,我们定义令牌化为:将含有不同成分的教育资源(如题目)转化为 含有不同类型令牌的令牌序列。
令牌化函数¶
底层接口¶
此功能对应的实现函数为 EduNLP.SIF.tokenize ,将已经经过结构成分分解后的item传入其中即可得到所需结果。
Note
此部分仅用于告知用户令牌化的涉及的操作(成分分解、语法解析),若用户不需要修改相关底层接口,建议直接学习 标准接口 或更加方便的 令牌化容器 。
- ::
>>> from EduNLP.SIF.tokenization import tokenize >>> items = "如图所示,则三角形$ABC$的面积是$\\SIFBlank$。$\\FigureID{1}$" >>> tokenize(seg(items)) ['如图所示', '三角形', 'ABC', '面积', '\\\\SIFBlank', \\FigureID{1}] >>> tokenize(seg(items), formula_params={"method": "ast"}) ['如图所示', '三角形', <Formula: ABC>, '面积', '\\\\SIFBlank', \\FigureID{1}]
标准接口¶
标准接口将标准化检验、成分分解、语法解析封装为一个整体,含有三个步骤的所有功能, 且提供多种参数以满足个性化使用需求。 具体使用方法见示例:
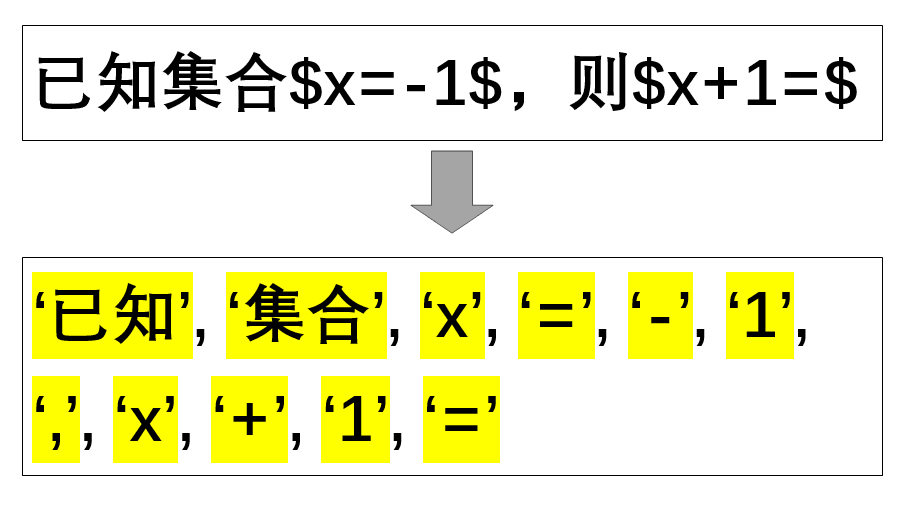
令牌化容器¶
我们提供了多种已经封装好的令牌化容器供用户便捷调用,通过查看 EduNLP.Tokenizer 及 EduNLP.Pretrain 可以查看更多令牌化器。下面是一个完整的令牌化器列表:
通用化的基础令牌化容器
TextTokenizer
PureTextTokenizer
GensimSegTokenizer
GensimWordTokenizer
适配特定模型的令牌化容器
ElmoTokenizer
BertTokenizer
DisenQTokenizer
QuesNetTokenizer
Note
“适配特定模型的令牌化容器” 需要与相应的T2V容器配合使用,本节仅介绍 “通用化的基础令牌化容器” 的使用方法。 如需查询ElmoTokenizer等令牌化容器,请前往预训练或向量化部分进行学习。
TextTokenizer¶
即文本令牌解析器,此令牌解析器同一般的文本分词器一样,采用线性解析方法得到令牌序列。其中,公式成分被视为文本,不关心公式的语法结构,作线性解析处理;而图片、标签、分隔符、题目空缺符等成分被转换成特殊字符,作符号化处理。此外,提供key参数用于选择传入的item中待处理的内容。
>>> tokenizer = TextTokenizer()
>>> items = ["已知集合$A=\\left\\{x \\mid x^{2}-3 x-4<0\\right\\}, \\quad B=\\{-4,1,3,5\\}, \\quad$ 则 $A \\cap B=$"]
>>> tokens = tokenizer(items)
>>> next(tokens)
['已知', '集合', 'A', '=', '\\left', '\\{', 'x', '\\mid', 'x', '^', '{', '2', '}', '-', '3', 'x', '-', '4', '<',
'0', '\\right', '\\}', ',', '\\quad', 'B', '=', '\\{', '-', '4', ',', '1', ',', '3', ',', '5', '\\}', ',',
'\\quad', 'A', '\\cap', 'B', '=']
>>> items = [{
... "stem": "已知集合$A=\\left\\{x \\mid x^{2}-3 x-4<0\\right\\}, \\quad B=\\{-4,1,3,5\\}, \\quad$ 则 $A \\cap B=$",
... "options": ["1", "2"]
... }]
>>> tokens = tokenizer(items, key=lambda x: x["stem"])
>>> next(tokens)
['已知', '集合', 'A', '=', '\\left', '\\{', 'x', '\\mid', 'x', '^', '{', '2', '}', '-', '3', 'x', '-', '4', '<',
'0', '\\right', '\\}', ',', '\\quad', 'B', '=', '\\{', '-', '4', ',', '1', ',', '3', ',', '5', '\\}', ',',
'\\quad', 'A', '\\cap', 'B', '=']
>>> items = ["有公式$\\FormFigureID{1}$,如图$\\FigureID{088f15ea-xxx}$,若$x,y$满足约束条件公式$\\FormFigureBase64{2}$,$\\SIFSep$,则$z=x+7 y$的最大值为$\\SIFBlank$"]
>>> tokenizer = get_tokenizer("text") # tokenizer = TextTokenizer()
>>> tokens = tokenizer(items)
>>> print(next(tokens))
['公式', '[FORMULA]', '如图', '[FIGURE]', 'x', ',', 'y', '约束条件', '公式', '[FORMULA]', '[SEP]', 'z', '=', 'x', '+', '7', 'y', '最大值', '[MARK]']
PureTextTokenizer¶
功能同 TextTokenizer , 且它会过滤掉经特殊处理的公式(例如:$\FormFigureID{…}$ , $\FormFigureBase64{…}$ ),仅保留文本格式的公式。
>>> tokenizer = PureTextTokenizer()
>>> items = ["有公式$\\FormFigureID{1}$,如图$\\FigureID{088f15ea-xxx}$,若$x,y$满足约束条件公式$\\FormFigureBase64{2}$,$\\SIFSep$,则$z=x+7 y$的最大值为$\\SIFBlank$"]
>>> tokenizer = get_tokenizer("pure_text") # tokenizer = PureTextTokenizer()
>>> tokens = tokenizer(items)
>>> print(next(tokens))
['公式', '如图', '[FIGURE]', 'x', ',', 'y', '约束条件', '公式', '[SEP]', 'z', '=', 'x', '+', '7', 'y', '最大值', '[MARK]']
GensimWordTokenizer¶
此令牌解析器默认对文本均采用线性的解析方法,而对公式采用抽象语法树的解析方法。此外,也可自定义符号化成分,将制定的成分(文本、公式、图片、标签、分隔符、题目空缺符等)转换成特殊字符,获得最终的令牌化序列,
若item不符合SIF标准格式,可通过制定参数 general=False 使用一般的文本处理方法来执行令牌化:
当general=true:代表着传入的item并非标准格式,此时将公式视为文本,使用线性解析方法;
当general=false:代表着传入的item为标准格式,此时对公式采用抽象语法树的方法进行解析。
>>> item = "已知有公式$\\FormFigureID{1}$,如图$\\FigureID{088f15ea-xxx}$, 若$x,y$满足约束条件公式$\\FormFigureBase64{2}$,$\\SIFSep$,则$z=x+7 y$的最大值为$\\SIFBlank$"
>>> tokenizer = GensimWordTokenizer(symbol="gmas")
>>> token_item = tokenizer(item)
>>> print(token_item.tokens)
['已知', '公式', \FormFigureID{1}, '如图', '[FIGURE]', 'mathord', ',', 'mathord', '约束条件', '公式', [FORMULA], '[SEP]', 'mathord', '=', 'mathord', '+', 'textord', 'mathord', '最大值', '[MARK]']
>>> tokenizer = GensimWordTokenizer(symbol="gmas", general=True)
>>> token_item = tokenizer(item)
>>> print(token_item.tokens)
['已知', '公式', '[FORMULA]', '如图', '[FIGURE]', 'x', ',', 'y', '约束条件', '公式', '[FORMULA]', '[SEP]', 'z', '=', 'x', '+', '7', 'y', '最大值', '[MARK]']
GensimSegTokenizer¶
功能同 GensimWordTokenizer,但GensimSegTokenizer解析器可以按分块的形式返回处理后的token,即保留item的结构信息:
提供了切分深度的选项,即选择按结构成分分块或语义成分分块, 且默认在文本块和公式块的头部插入开始标签。
选择分块级别
depth=None: 按结构成分分块, 即按模态类型,返回文本、公式、图片的token列表
depth=0 选择在sep标签处进行切割
depth=1 选择在tag标签处进行切割
depth=2 选择在sep标签和tag标签处进行切割
item = "已知有公式$\\FormFigureID{1}$,如图$\\FigureID{088f15ea-xxx}$, 若$x,y$满足约束条件公式$\\FormFigureBase64{2}$,$\\SIFSep$则$z=x+7 y$的最大值为$\\SIFBlank$"
tokenizer = GensimSegTokenizer(symbol="gmas")
token_item = tokenizer(item)
print(len(token_item), token_item)
# 10 [['已知', '公式'], [\FormFigureID{1}], ['如图'], ['[FIGURE]'], ['mathord', ',', 'mathord'], ['约束条件', '公式'], [[FORMULA]], ['mathord', '=', 'mathord', '+', 'textord', 'mathord'], ['最大值'], ['[MARK]']]
# segment at Tag and Sep
tokenizer = GensimSegTokenizer(symbol="gmas", depth=2)
token_item = tokenizer(item)
print(len(token_item), token_item)
# 2 [['[TEXT_BEGIN]', '已知', '公式', '[FORMULA_BEGIN]', \FormFigureID{1}, '[TEXT_BEGIN]', '如图', '[FIGURE]', '[FORMULA_BEGIN]', 'mathord', ',', 'mathord', '[TEXT_BEGIN]', '约束条件', '公式', '[FORMULA_BEGIN]', [FORMULA], '[SEP]'], ['[FORMULA_BEGIN]', 'mathord', '=', 'mathord', '+', 'textord', 'mathord', '[TEXT_BEGIN]', '最大值', '[MARK]']]
